对抗生成网络
介绍
GAN 是一种神经网络,从 2014 年开始出现。它的应用非常的有趣,而且在生成数据方面有令人惊喜的效果。 在现实生活中,从文本到图像再到视频都有 GAN 的应用。

让机器生成东西,生成图像,写诗。要做的就是训练一个 generator, 例如输入一个 vector 通过一个 NN generator 生成一个图像。
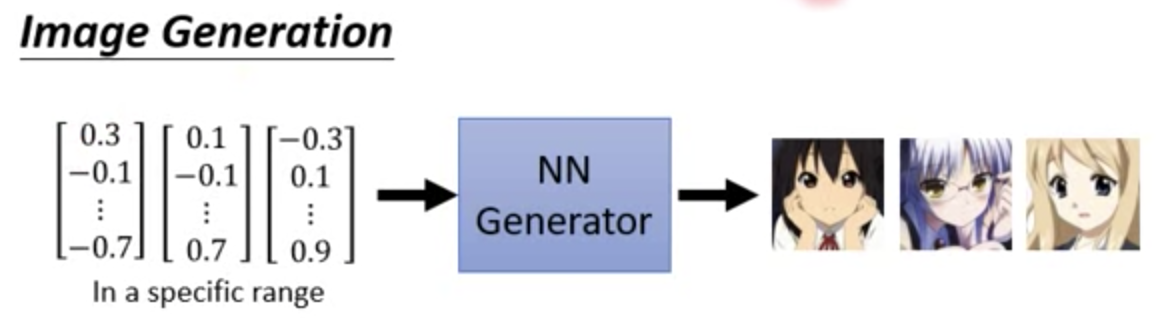
generator 就是一个 NN,GAN 中 input 就是一个 vector,在 image 中 output 就是一个 image(high dim vector)
例如在二次元生成的应用中,一个维度的输入对应到某一个特征,所以改变某一个量,生成的内容会有稍微的不同。

在 GAN 中同时要训练一个 Discriminator, 也是一个 NN。它的输入和输出

输入一个图片,输出一个 scalar(一个数字,代表生成图的质量)。
generator 和 disciminator 关系类似捕猎者和猎物的关系,不断的进化。
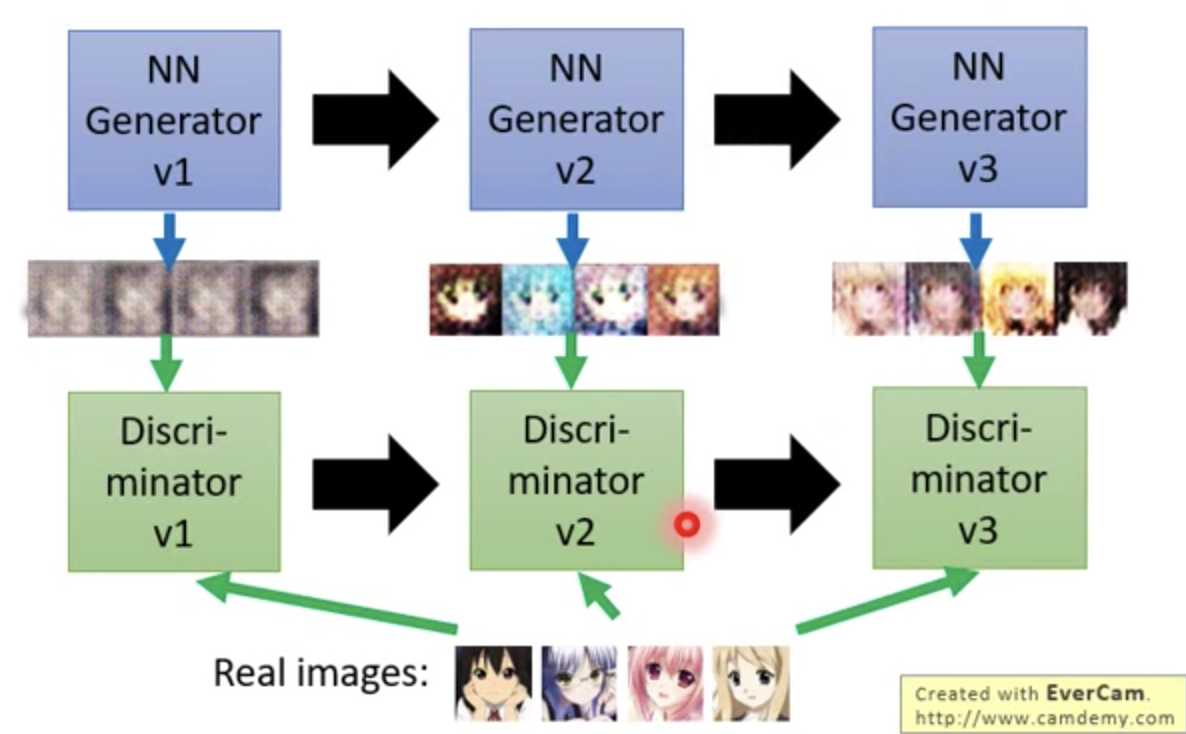
Generator 生成一组图像,然后第一个代的 Discriminator 就判断这个图像和真实的图像的差异。同时 Generatorv2 跟着进化,生成另一组图像试图骗过 Discriminator。
用老师和学生的比喻可以这样理解: G v1 是一年级的学生,画了些不太好的图像,D v1 是一年级的老师指出,它的画和真实的画差别在哪里。 G v2 是二年级的学生,它改进了 D v1 指出来的问题,D V2 是二年级的老师,又指出了新的问题。
所以现在有了一个问题,G 为什么不能自己学习呢?非得弄一个 D 来教给它。同样,D 这么懂,为什么不自己做呢?(星星眼)
如何操作的
- 初始化 G D
- 在每一次的迭代中:
- step1: 固定 G,更新 D
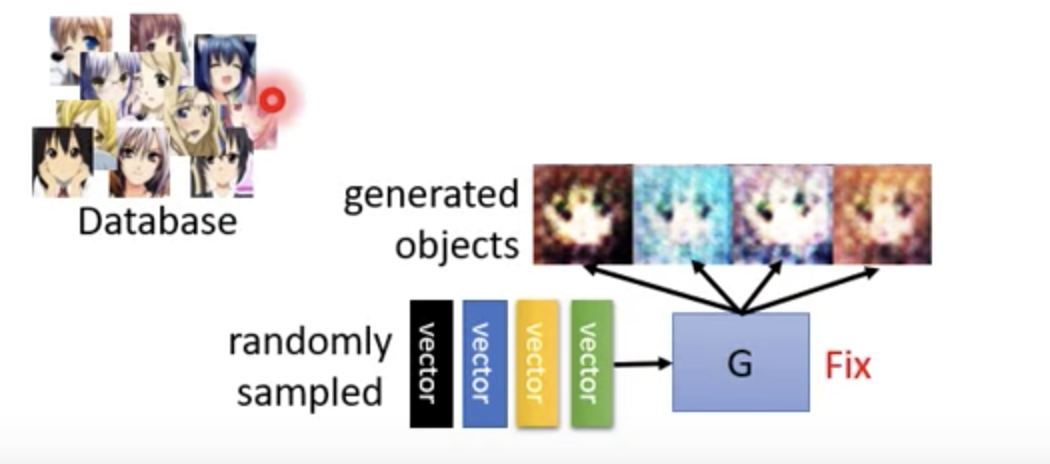
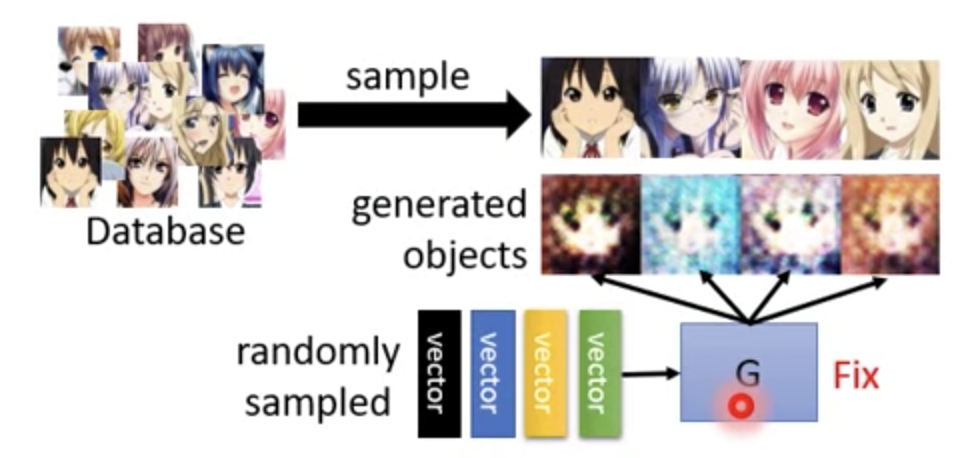
我们的目标就是将 databse 里出来的图,放到 D 中能够 output 一个高的分数。 G 生成的图,丢到 D 中 output 一个小的分数。
step2: 固定 D,更新 G
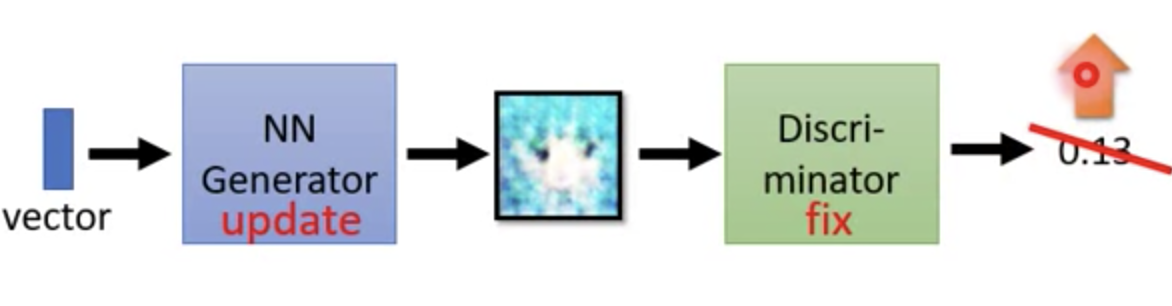
基本想法就是,让 G 尽量的骗过 D,让它生成一个高的分数。在实现的时候其实就是将 G 和 D 合成一个大的神经网络。图片作为一个 hidden layer,例如一个图是 64*64。我们就调整前面的几个 layer,固定后面的 layer。
具体的算法是这样的:

注意里面的目标函数,我们的目标是 max(V)。
概念上理解 GAN
GAN as structured learning: 找到一个 f 能够做 f: x->y
例如 image2image, text2image:

one-shot / zero-shot learning: 类似对某一个机器没有见过或很少见过的东西,它能否分辨出。
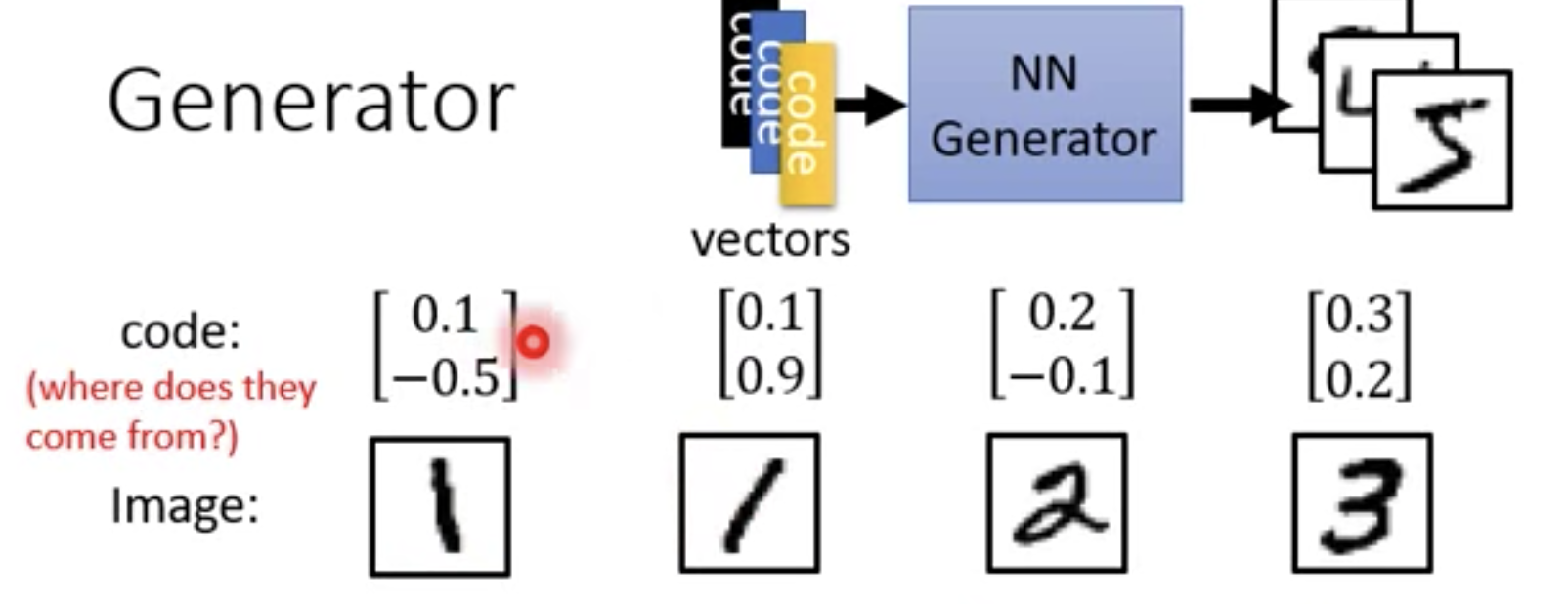
在数字生成中,我们的向量怎么来,比如两个 1,我们想要它们的 vector 中有某些地方是相似的,如果随机生成可能就不行了。
这里我们可以用一个 Encoder:
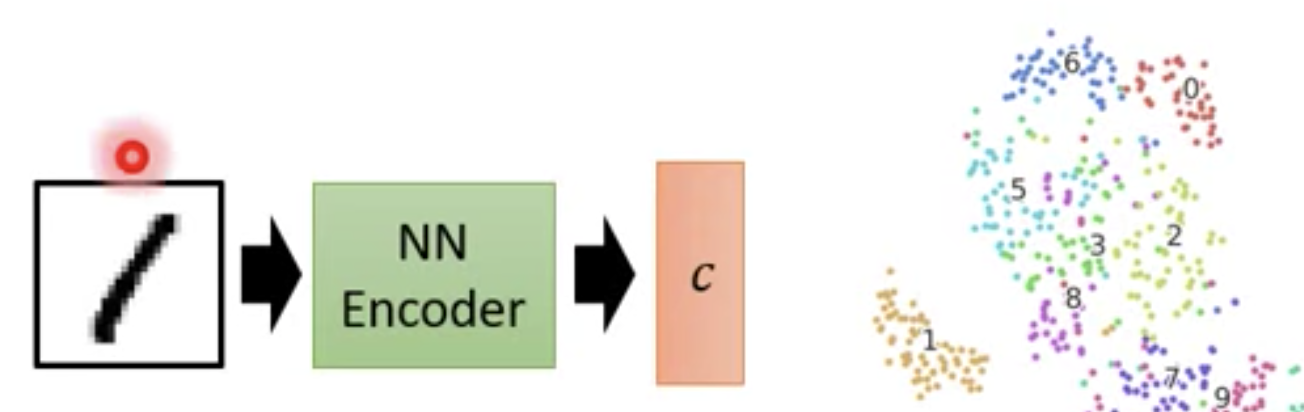
可以使用 Auto-encoder, 我们需要一个 Encoder 和 Decoder
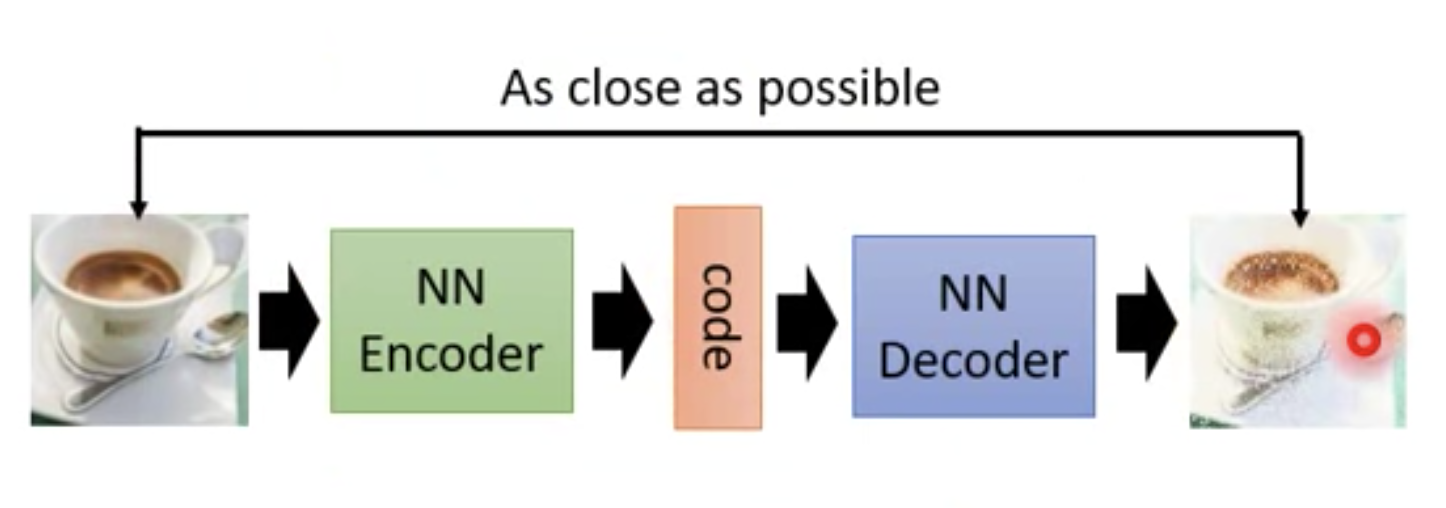
todo
实现一下 Anime face generation